
Arun Kumar is an Assistant Professor in the Department of Computer Science and Engineering and the Halicioglu Data Science Institute at the University of California, San Diego. His primary research interests are in data management and systems for machine learning/artificial intelligence-based data analytics.
His Advanced Data Analytics Lab (ADALab) focuses on basically improving machine learning and artificial intelligence-based data analytics from a holistic standpoint of concerns such as scalability, usability, ease of deployment, ease of development. He calls all of this democratization of machine learning-based data analytics. He is building software systems, abstractions, tools, devising new algorithms, and also studying the theory behind empiricism. The experimental analysis behind this whole process of making machine learning-based analytics easier, and faster, and cheaper for people.
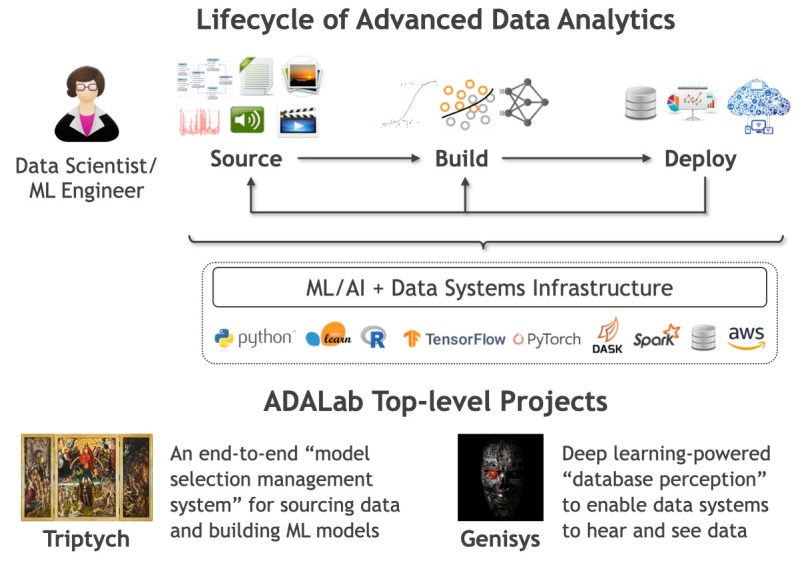
The lifecycle of advanced Data Analytics consists of three phases which are sourcing, building and deploying. The sourcing stage consists of converting raw data in data lakes and data warehouses into ML-ready data. Data preparation is basically reformatting the data. In the second step, the build stage is converting that into a prediction pipeline. MLflow is one of the tools that people use for standardized data. The building stage is where a lot of machine learning and data mining classes focus their efforts on things like how to prepare features. For data scientists, the first thing they need to worry about is defining the application goal. Finding out how data is going to achieve something for the application is the first step towards finding the application goal. The objectives themselves are a big bottleneck, for a lot of users of machine learning.
Data building involves applying the knowledge to the algorithms and the theory of machine learning and connecting them with the application goals that users have. Fairness, inference latency, training cost, interpretability and explainability of data are things that matter significantly. Finally, the deploying step is integrating a prediction pipeline with an application and monitor and oversee the life cycle as the data and application evolve.
Over the last couple of decades, the complexity of the model deployment landscape has exploded due to cloud computing, the internet of things (IoT), heterogeneity of hardware and models. All of these things have caused an explosion of complexity. In the web companies, app companies and the IoT world, deployment is very heterogeneous, and the machine learning environment is no exception. Usage of MLflow, TensorFlow Extended (TFX) and TensorFlow Serving makes it easier for people who do model building and data sourcing. Hence, users can build prediction pipelines.
In these three stages, the amount of scientific inquiry scientists have is still not at the level that they want it to be. A big portion of the computing research in his lab is fundamentally answering questions like, What are practitioners doing accurate enough? Can we reduce the cost and improve productivity? Arun Kumar says he has to interact with practitioners to understand where the bottlenecks are.
One of the projects in Arun’s Data Analytics lab focuses on Project Cerebro. In the Cerebro project, they propose a new system for Artificial neural network (ANN) model selection that raises model selection throughput without raising resource costs. Their target setting is small clusters (10s of nodes), which covers a vast majority (almost 90%) of parallel ML workloads in practice. We have four key concerns: scalability, statistical convergence efficiency, reproducibility, and system generality. To satisfy all these, they develop a novel parallel execution strategy.
There are many tradeoffs that are inherent in a real-world application of ML. For instance, correct model selection is a key bottleneck in raising the accuracy of the data. The Cerebro project aimed at making the process of model selection easier. Arun and his coworkers want to make a sort of high-throughput exploration process so that they will reduce resource costs and reduce runtimes. Therefore, people will be more willing to do more of the sort of exploration and reach better accuracy and better metrics. And that was what they observed in the Cerebro project. He says that is what motivated them to build out the Cerebro system. The Cerebro system was designed in a way that scientists planned to use the tools that they are comfortable with. So they don’t have to change their TensorFlow, PyTorch or Kerris implementation.
The Data stored on data lakes, data warehouses and database systems. Colleagues of Arun Kumar at VMware would like to do machine learning tasks like sentiment mining and named entity recognition. Hence, they could just specify the off-the-shelf transformer architectures, doing hyperparameters for fine-tuning on the data sets, and then give that to the Cerebro API’s, and then they could build it at a higher throughput. This is an example of an application that uses Cerebro as a tool to improve model selection.
Arun Kumar says, “Any prediction task where you would need to build a model and need to tune hyperparameters, need to tune the architecture, Cerebro is useful there. It’s really a very general system for all these sorts of model selection tasks, where you’re building a neural computational graph.”
Neural computational graph frameworks that they currently support are TensorFlow and PyTorch. They are the most commonly used frameworks for specifying neural computation graphs, and executing them and training them with Stochastic gradient descent (SGD). In the future, it can be extended to other frameworks as well.
Cerebro project born out of academic needs. Big corporate companies like Google, Amazon or Facebook could try to solve a problem with 100 GPUs. However, this is not the case in academia. In academia, people need to share their total computation power properly so that everyone on the campus could benefit from it. The technique of model parallelism in Cerebro mitigates the cons of this kind of shared usage. Arun and his team invented Cerebro because they find it necessary for academicians like themselves and also for a lot of domain scientists, academics, enterprises and tech companies.
Regarding excessive usage of resources in the big technology corporations, Arun Kumar says, “They think they could just throw machines at everything and get away with it. And in turn, it comes back to bite people. Like if you’re in the cloud, and you’re just throwing machines at it, who is going to benefit from it? It’s the cloud vendors because they can pocket more money from the enterprises.”
The importance of resource efficiency is one of the reasons why the Cerebro project took this course. VMware is also a big tech company. But their philosophy is very different from all these other companies. Arun believes big tech companies and cloud providers will eventually come around to this worldview because if they’re going to sell products to enterprises, enterprises are going to demand bills that are lower than what they have today.
For the future of data science, Arun thinks, problems are getting wilder and less well-defined. Hence, there will be a lot of research attention that is going to be needed. Scientists need a lot more work on data preparation and data sourcing part of the lifecycle from the scientific and research standpoint. There is also a need for more industry-academia partnerships on the deployment side.
This summary is based on an interview with Arun Kumar, Assistant Professor in the Department of Computer Science and Engineering and the Halicioglu Data Science Institute at the University of California, San Diego. To listen to the full interview, click here.
The post Episode Summary: Data Management Systems and Artificial Intelligence with Arun Kumar appeared first on Software Engineering Daily.
* This article was originally published here







No comments: